在做二分类任务的时候,往往可采用的方法有很多,比如 对数几率回归 或者树模型(往往是 随机森林 , GBDT 这一类集成模型),当然还有很多种办法, 感知机 就是其中的比较直观和简单的一种,感知机的原理很简单,考虑在特种空间中的 线性可分 的数据集,是能够找到一条 分类超平面把两类数据给正确区分开的,这个不是这里要讨论的重点,这里要讨论的是这种很显然有 无数种超平面使两分类正确分类的时候如何找到”最好“的那一条,有了“最好”的限制条件,就成为了这里要说的 SVM
Support Vector Machine
感知机
感知机是 二分类的线性分类模型 ,感知机要做的事是在训练数据中找到一个 超平面,将数据分为正例和负例两类,其输入就是数据的特征向量,这里简单的说一下感知机的过程,主要是为了引出后面的SVM,这里只考虑线性可分的情况
首先给定数据集 \( D={(x^{(1)}, y^{(1)}), (x^{(2)},y^{(2)}),\cdots,(x^{(N)}, y^{(N)})}\) ,其中 \( x^{(i)}\in R^n\),\( y^{(i)}\in {-1, +1\\}\) \( i = 1,2\cdots,N\),如下图所示的红色和蓝色的点,这里不是回归问题中的拟合一条直线去逼近这些数据点,而是找到一条直线将两类数据划分开,考虑二维空间中直线的公式为 \( y=ax+b\) ,这里 \( x,y\) 是可以看成是数据点的两个维度可以转化成 \( x_1,x_2\) ,于是直线就可以改写成 \( ax_1-x_2+b=0\) ,可以更进一步的写成向量 的形式
此时感知机模型表示为 \( y = sign(\theta^T\cdot x + b)\) , \(sign\) 为 符号函数 ,此时定义感知机的损失函数之前需要明确以下几点
- \( \theta^Tx+b=0\) 这条直线将数据分为两类,那么就满足 \( theta^Tx+b>0\) 为正例输出 \( y=+1\) , \( \theta^Tx+b<0\) 为负例输出 \( y=-1\) ,此时对于正确分类的数据来说 \( y^{(i)}(\theta^Tx^{(i)} + b) >0\) ,分类错误的数据则为 \( y^{(i)}(\theta^Tx^{(i)}+b)<0\)
- 数据点到直线的距离 \( \frac{|\theta^Tx+b|}{||\theta||_2}\)
所以定义感知机的损失函数可以 让误分类的数据到直线的距离和最小 ,因为是针对误分类数据的,所以损失函数这么写
这里 \( M\) 为误分类点的个数,同时发现 \( \frac{1}{||\theta||_2}\) 可以不考虑,因为这里是针对 误分类 的数据构建的损失函数,即在没有误分类的情况下损失最小为 \( 0\) ,此时 \( \theta,b\) 取任意值都可以,且 \( ||\theta||_2\) 是 \( \theta\) 的L2范数,也就是损失函数的一个 常量因子 ,所以感知机的损失函数和 \(\theta, b\) 的偏导数即是
有了损失函数和 \( \theta, b\) 的偏导,就可以利用 梯度下降来对其进行迭代求解,这里不再赘述了,感知机说到这里主要有一个问题,就是感知机的这个超平面是有无数个的,比如下图所示的线性可分的数据,在两条黑色虚线的间隔中,可以画出无数条直线能够完美的将数据划分开,那么是否能找到最好的一条呢?
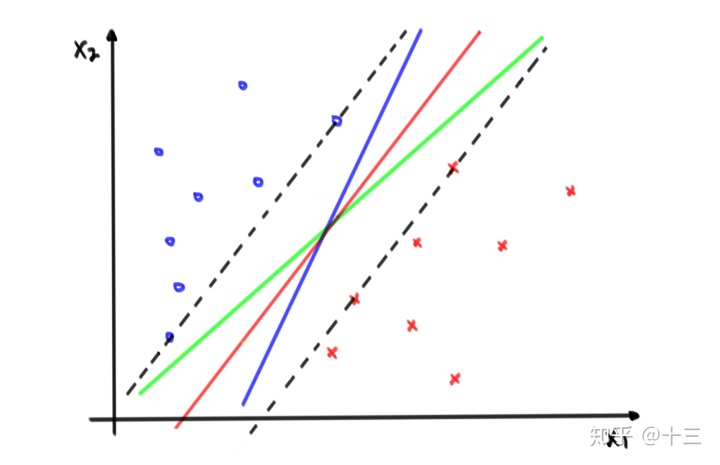
从图上可以直观的看出来,蓝色和绿色的直线虽然也能将数据划分开,但是都或多或少的向某一边“ 倾斜 ”,所以这里要找的内条“最好”的直线是指这条线是 以“最可靠”的方式来划分 的,不但将训练数据正确划分,也能够对未知数据有足够的可信度将其分开 ,从图中也显然能观察出来间隔中间红色的直线要好于另外两条, SVM就是找到这条红线的一种方法。
硬间隔线性可分SVM
首先只讨论数据集线性可分的情况,给定数据集\(D={(x^{(1)},y^{(1)}),x^{(2)},y^{(2)}),\cdots,(x^{(N)}, y^{(N)})}\) ,其中 \( x^{(i)}\in R^n\) ,\( y^{(i)}\in {-1, +1}\) ,根据前面对感知机的了解,要同时满足两个条件才能确定这个超平面
- 正确分类正例和负例,且要让数据,分布在间隔上或者间隔外,因为如果有数据还在间隔内,那显然间隔的划分的是有问题的
- 两类数据中间的 间隔要足够大 ,这样间隔中间的这条线才是足够可靠的
结合下面的图来具体的说一下SVM的优化方向
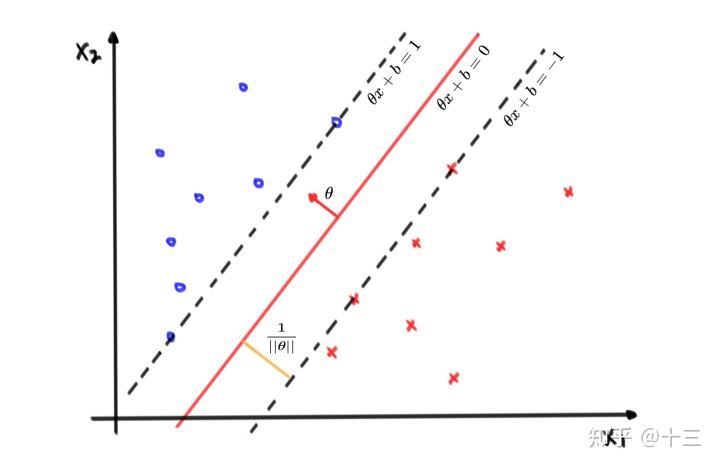
根据SVM正负例都在间隔上或者间隔外这一特点,如果数据被正确分类的话就会有数据点的 几何间隔 符合
不等式左右同时除以 \( d\) ,不等式变换为
上式中主要关注 \( \frac{\theta^T}{||\theta||d}\) 和 \(\frac{b}{||\theta||d}\) ,这时候可以发现, 事情本质并没有发生什么变化,这两个值只是在 \(\theta^T,b\) 的基础上对其数值大小进行了一定的缩放 ,就仍然可以写成
综合上面2种情况将 \( y^{(i)}\) 乘进去就可以变成一个不等式 \(y^{(i)}(\theta^Tx^{(i)}+b)\geq1\) ,这就是SVM优化问题中的 约束条件 ,下面来讨论最大间隔这件事儿
首先要知道 最大几何间隔的表达方式 ,图中看的更直观一些,首先这个最大间隔到底能有多大,其实是取决于在间隔边界上这些数据点,这些点叫做支持向量 ,SVM的超平面也是主要取决于这些支持向量,几何间隔计算也不困难,定义几何间隔为 \( d\)
所以想要最大间隔的 SVM的损失函数即是这样定义的,在满足约束条件的同时最大化几何间隔
其中这里 \( \mathop{max}_{\theta}\frac{1}{||\theta||}\) 表示最大化,效果也等价于 \( \mathop{min}_{\theta} \frac{1}{2}||\theta||^2\) ,\( \frac{1}{2}\) 也容易理解,是为了方便求导计算,并不影响 \( \theta\) 的优化,所以至此硬 间隔线性可分SVM 的损失表示就为
但是这个损失函数并不是单独的一个式子,而是 有约束的 ( \( s.t.\) 为 subject to的缩写)的损失函数,其意思呢就是在 \( s.t. \space y^{(i)}\theta^Tx^{(i)}+b)\geq1\) 这个 可行解空间中 去优化 \( \mathop{min}_{\theta}\frac{1}{2}||\theta||^2\) ,这部分在下一篇 SVM(二) 中主要讨论。
😛