在文章《 决策树 》中讨论了简单决策树的构建,最后提到了决策树算法很容易引起过拟合问题,就是说当决策树贪婪的学习到“最优”的状态的时候,很容易就把数据中的一些噪声或者离群点当成正确的数据学习了进去,那么很显然会对模型的精度产生一定的影响,所以往往需要剪枝,让决策树的泛化能力更好一些,但是这里介绍另外一种更好的方法来让模型避免学习到噪声数据,从而提升模型的精度。
集成学习 Ensemble Learning
集成学习是一种机器学习思想,可以比喻成“ 三个臭皮匠赛过诸葛亮”,就是说单个模型并不能很完美的解决某个分类或者回归问题的时候,那么就训练出多个模型,每个模型可能是相同的也可以是不同的,比如模型1是决策树,模型2是朴素贝叶斯等等,然后预测的时候将数据分别输入每个模型,最后将每个模型的输出综合起来作为该未知数据的输出,下面就简单的讨论两种比较常见的集成学习算法
随机森林 Random Forest(Bagging)
随机森林是通过集成学习的思想将多棵树合并到一起的算法,它的基本单元就是决策树,最终通过多个决策树的“ 投票 ”( 决策树输出的众数)结果作为最终的输出,随机森林理解起来主要是“ 随机 ”和“ 森林 ”两部分。
- 森林:很多树(决策树)放在一起,不就是形成了“森林”嘛
- 随机:随机地从 \( M\) 特征中选取 \( m\) 个特征( \(m < M\) ),且随机有放回的选取样本 \( n\) ( \( n \ll N\) ,\( N\) 为总样本数),单独的训练每一棵树
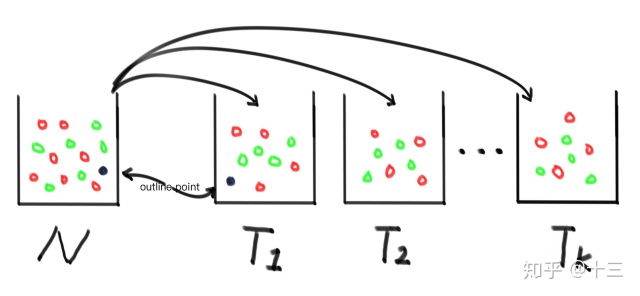
\( N\) 表示所有训练数据, \( T_1, T_2...T_k\) 为抽取子集训练的不同的决策树,如下为几个 tips :
- 为什么采用有放回的方式采样 。因为否则的话,每棵树的训练集都是不同的,都学习到了整体数据集的一部分规律,有点“ 盲人摸象 ”的意思
- 为什么能够避免过拟合 。因为过拟合大多数是因为噪声数据造成的,模型把噪声的异常数据当成数据的规律来正常学习了进去,所以导致过拟合,而采用这种随机采样的方式来做的话,图中所示的 \( outline \space point\) 就只会被少数的决策树采样到,这样在最后“投票”的时候,大多数决策树学到的还是正确的规律
- 因为每个树的采样和训练都是 互相独立 的,所以这里很容易把整个森林中的每棵树 并行训练 ,提高训练速度
- \( oob \space errors \space (out \space of \space bag \space errors)\) 即为袋外错误率,在构建每棵树的时候都有一部分的数据没有落入该决策树的采样集中,这部分数据即为该决策树的袋外数据,这部分数据的错误率即为袋外错误率,这样也避免了模型训练完之后需要大量计算的 交叉验证 ,在模型内部即可得到该误差的无偏估计,同时随机森林中的特征重要程度也是通过 \( oob \space errors\) 计算出来的
随机森林的通用形式即为
随机森林中 feature_importance 的计算
- 对于“森林”中的每一棵树, 选择一定的袋外( oob )数据来计算误差 ,假定这里为 \( oe1\) ( oob errors 1)
- 给所有样本的 某一个特征 \( X\) 随机添加噪声数据 ,再次计算误差,这里为 \( oe2\)
- 假设有 T 棵树,则该特征 \( X\) 的 feature_importance 即为 \( \frac{1}{T}\sum_{i=1}^{T}{(oe2_i-oe1_i)}\) ,这里也很好理解, 误差相差越大,其实就是随机加入的噪声特别影响特征 \( X\) ,也就是说特征 \( X\) 是比较重要的
自适应增强 AdaBoost(Boosting)
上面说的随机森林算法中其实默认了一个情况,就是 \( T_1, T_2...T_k\) 这些决策树的 权重是一样的 都为 \( \frac{1}{k}\) ,但是其实这是不足够合理的,因为决策树总会有正确率高的和低的,更合理的做法其实是高的决策树权重更高 , 正确率低的决策树权重更低甚至丢掉该决策 树,这样会让整个模型更加准确, AdaBoost算法即是针对这种情况做出的优化,其核心思想是 针对同一个训练集训练不同的弱模型 ,然后把这些弱模型组合起来形成一个更强的模型,算法本身是通过改变数据的分布 来实现的,数据本身也有权重,将错分的数据也提高权重来更关注这部分数据。
算法的详细步骤:
- 将样本数据集中的每一个样本数据初始化一个权重 \( w^{(i)}\)
- 通过对整体样本集的学习得到第一个 弱模型 \( G_k\)
- 计算该弱模型的 错误率 \( e_k\)
- 计算该弱模型的 权重 \( \alpha_k\)
- 更新样本数据的权重 \( w\)
- 用更新后的权重数据训练第二个弱模型 \( G_{k+1}\)
- 然后不断 循环2-6步 ,最终由 \( k\) 个弱模型得到一个准确率更高的模型 \( F(x)\)
现有训练集 \( D ={(x^{(1)}, y^{(1)}), \space (x^{(2)}, y^{(2)}), \space (x^{(N)}, y^{(N)})}\) , \( x^{(i)}\in R^n, y\in {-1, +1\\}\)
1. 对每一个数据 \( x^{(i)}\) 初始化 一个权重 \( w^{(i)}\)
2. 针对 \( k = 1, 2, ..., K\) 训练一个弱模型, \( G_k\) ,这里 \( k=1\)
3. 计算错误率 \( e_k\) ,这里 \( I\) 为 indicator函数,计数为True的个数,这里实际上就是计算所有数据中 错误的加权比例 而已
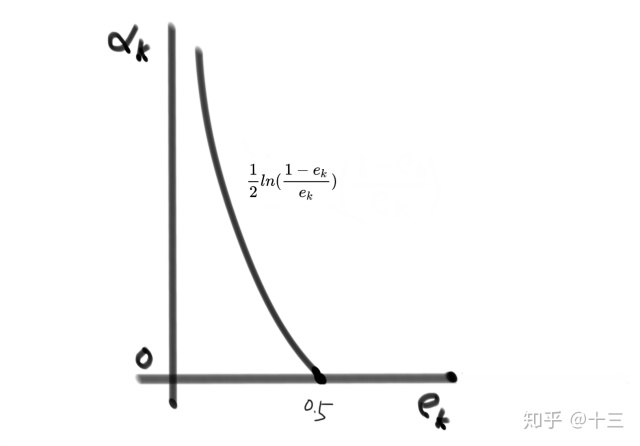
4. 通过 \( e_k\) 计算 \( G_k\) 的权重 \(\alpha_k\) ,这里是应用下面图示关系曲线来计算的,结合函数曲线其实也很容易理解,就是说该第 \( k\) 个弱模型的错误率越低 ,那么这个 弱模型的权重就越高 ,这里 \( 0.5\) 是个很有意思的点,如果在2分类问题中一个模型的正确率为 \( \frac{1}{2}\) ,那么这个模型实则是没有任何作用的,蒙一下也能达到这个正确率,所以对于这种模型来说就是可以丢掉的,权重也就是 \( 0\)
5. 更新样本数据的权重 \( w_k^{(i)}\Rightarrow w_{k+1}^{(i)}\) ,这里 \( k,k+1\) 代表第 \( k, k+1\) 轮迭代
这里先不考虑 \( Z_k\) 因为它只是一个 归一化系数 ,最终达到的效果就是每一轮迭代之后让所有样本的权重之和为 \( 1\) ,此时有两种情况,当错 分的时候就会提高该错分数据的权重
- 如果 \( y^{(i)} G_k(x^{(i)})=1\) 为分类 正确 ,那么 \( w_k^{(i)}exp(-\alpha_k)\) 下降
- 如果 \( y^{(i)} G_k(x^{(i)})=-1\) 为分类 错误 ,那么 \( w_k^{(i)}exp(-\alpha_k)\) 上升
6. 用更新权重后的数据训练第下一个弱模型,然后不断迭代最终得到一个强模型 \( F(x)\)
总结
- 二者都是基于集成学习思想构建的一种算法,都能避免一定的过拟合问题,让模型泛化能力更好,准确率也更高
- 随机森林因为采样的动作,且每棵树是独立的,所以更容易 并行 ,训练效率很高,而AdaBoost则不可以,因为每一个弱模型都 依赖于上一个弱模型 ,所以无法并行训练
- 随机森林由于不但样本采样,数据特征也做了采样,所以对 特征工程 要求就不是那么严格,而AdaBoost则没有采样动作
😛