今天来研究一下分类问题中的决策树,决策树从名字就可以看出来,是一种树形结构的决策模型。如标题图中所看见的,我们想通过是“否拥有房产”、“是否已婚”、“年收入”这3个维度,来判断该客户是否具有偿还某种贷款的能力,就可以建造一个这样的1个树形结构模型,但是这其中有两个问题:1,为什么判断顺序是图中所示的顺序;2,为什么拥有房产为“是”的时候就停止向下判断,这里简单介绍几种决策树相关的算法。
信息论 Information Theory
信息论目的是寻找一种可以量化的方法,来量化信息量的多少,针对这个问题我们就可以对事件 \( X\) 做出如下基本的规律总结
- 事件的发生,最多是没有产生任何信息量,不可能还少了信息量,所以信息量是 大于等于0 的
- 考虑这样2个事件,A: 领导说今天晚上加班;B: 领导说要给你升职加薪。很明显B事件的信息量要大于A事件,且 \( P(A) > P(B)\) ,所以这里认为 信息量与该事件的发生概率成反比
- 多个 独立 事件的信息量为每个事件的信息量之和
所以事件 \( X\) 与该事件的信息量 \( Info(X)\) 可以得出这样的等式,来满足上面的3个要求
信息熵 Information Entropy
信息熵也叫香农熵,是香农于1948年10月发表的论文《通信的数学理论》中提出的,在该文中,香农给出了信息熵的定义,即是信息量的数学期望
其中 \( \chi\) 为有限个事件 \( X\) 的集合, \( X\) 是定义在 \( \chi\) 上的随机变量,是随机事件 不确定性的度量 ,如果事件为连续变量,即是把 \( \sum_{}^{}{}\) 变成 \( \int_{}^{}\) 求曲线积分。
信息增益 Information Gain
信息增益是系统从一个状态变成另一个状态之后,信息熵变小(系统 纯净度增大 或者系统的 不确定性减少 的程度)的增益效果量化。状态变更之前叫做初始状态熵 ,状态变更之后叫 条件熵 ,信息增益就是 初始状态熵 - 条件熵
\( w_i\) 为切分之后每部分的频率,也就是加权的概念,切分的越好,各部分的信息熵越小,信息增益也就越大。比如说 \( X\) 为“明天下雨”这一随机事件, \( Y\) 为”明天阴天“这一随机条件,二者的信息熵都是可以通过事件的概率计算出来的,这里假如
此时信息增益为
在得知“明天阴天”这一事件后,“明天下雨”的 不确定性减少了0.9 ,所以 信息增益增大,换句话就是说,”明天阴天“这一事件对于“明天下雨”这一事件来说是很重要的,所以决策树可以用信息增益( \( IG/ 重要程度\) )来判断节点的顺序
基尼指数 Gini Index
基尼指数是一个经济学系数,最初应用在判断年收入分配公平程度上,后来也应用于其他领域,代表了 模型的不纯度 ,基尼指数越小,则不纯度越低,特征越好 ,基尼指数的定义如下
\( P(j|X)\) 即是针对事件 \( X\) 中, \( j\) 类的频率,若给定样本 \( N\) , \( C\) 把 \( N\) 分为 \( C_1,C_2\) 两部分,则基尼系数为
即两部分的 加权 基尼指数, \( C\) 切分的越好,系统纯度越高,系统不纯度越低,基尼指数越小,这样通过不断的计算,找到最小的基尼指数即切分点,也可以遍历计算最终形成决策树
分类和回归树 CART Classification And Regression Tree
CART是一个二叉树,从名字就能看出来CART可以用来处理 分类 和 回归 问题,构造CART的过程是 递归地构建二叉决策树 的过程
分类树 通常采用Gini指数来构建树,即分别计算所有特征的Gini指数,然后用最小Gini指数的特征及相应的划分方式作为根节点和该特征的划分方式 ,然后在其他维度上重复进行此操作,最终形成分类树
回归树 处理的是连续变量,通常采用 最小均方误差 的方法来构建,通俗讲起来就是,在 \( j\) 个维度上,找到最优的切分点 \( s\) ,使得划分出来的 \( D_1, D_2\) 两部分数据的均方误差最小 ,总结起来的公式如下
\( L_2\) 表示欧式距离 \( c_1, c_2\) 为 \( D_1, D_2\) 两部分数据的均值,一般情况下递归的过程中,有这样几种情况的时候,就可以停止分裂
- 节点中的 样本数量小于阈值
- 节点中的 Gini指数小于阈值 ,则代表分类足够好
- 没有更多的特征可以分裂了
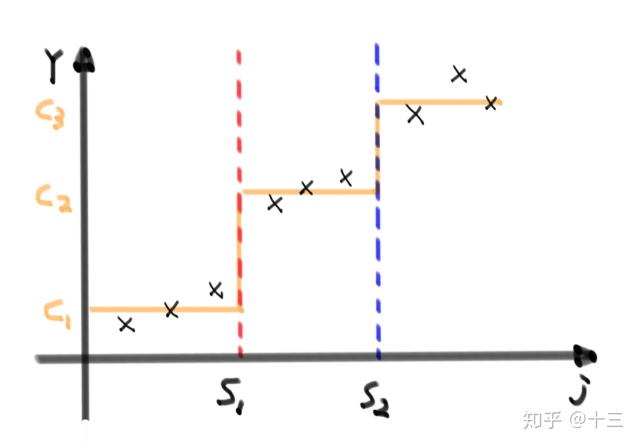
回归树举例来说,针对一维数据集(多维的情况只是遍历的时候也要遍历其他维度来寻找最好切分点),通过以下过程可以形成回归树
- 在 \( j\) 轴上遍历计算各个切分点的 \( Cost\) ,找到 \( s_1\) 点
- 在 \( j\) 轴上的 \( s_1\) 点处将数据切成左右两部分(红色虚线左右)
- 红色虚线左部分 \( c_1\) 停止分裂(误差小于阈值),右部分继续二分
- 在右部分遍历计算 \( Cost\) 找到切分点 \( s_2\)
- \( c_2, c_3\) 部分误差均小于阈值,所以停止分裂
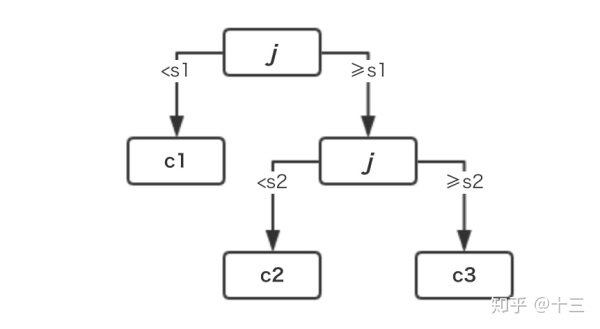
至此回归树简历完成,形成的树形结构为
总结
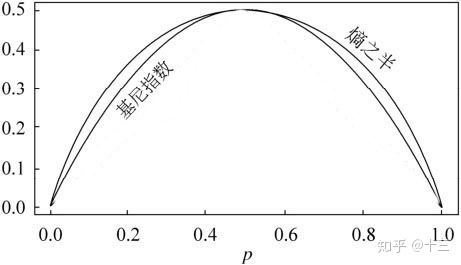
信息熵、基尼指数二者的图像曲线关系如下,熵之半即是 \( Entropy/2\) ,二者的图像很相似,即 \( p=0.5\) 时,熵和基尼指数都 到达最大 , 即最不稳定
决策树模型简单,易于理解,但是普通的决策树构造过程是 贪婪的,所谓贪婪就是决策树会一直分裂下去,直到没有更多的特征可以分裂了,所以对于普通的决策树来说 过拟合 很常见,这样一来就需要 剪枝使模型提前终止分裂( 预剪枝 )或者对完整的树进行剪枝( 后剪枝 )来让模型更简单、泛化能力更好,或者用 集成算法 来避免过拟合问题
😛