这次继续聊Boosting模型,上一篇聊了AdaBoost,AdaBoost的核心思想是通过提升错分的数据权重,来更关注错分的数据,同时根据每次迭代的正确率来给当前的弱模型一个权重,这个弱模型准确率越高,则这个弱模型的权重就越大,这是合理的,但是其实这样还是不够直接,更直接的做法是比如说第一次训练了一个弱模型,这个弱模型肯定不会是100%完美的,肯定会存在一定的误差(残差),此时更直接的想法就是我再训练一个模型来把这部分误差学习出来,然后两个模型叠加就可以了,但是此时肯定还不是完美的,不要紧,下一次迭代的时候再学习剩下部分的误差,从而让误差越来越小,这就是今天要聊的GBDT的所做的事情。
梯度提升树 GBDT
类似Boosting的思想,GBDT也是采用 分步迭代 学习弱模型的方式来学习最终的模型的,但是这里是学习了一个弱模型之后,在不改变这个弱模型也不改变数据的权重(AdaBoost)的基础上,学习另外一个弱模型,然后二者组合起来作为第二轮的模型,这样在不断学习并且模型不断累加的过程中让这些弱模型组合成表现更好的强模型
假设现在有数据集 \(D={(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),\cdots,(x^{(N)},y^{(N)})}\) ,其中 \( x^{(i)}\in R^n\) ,在第一轮的时候初始化一个树结构模型: \( H_0(x) =0\) ,就是说对每一个输入的 \( x\) 都给同一个值,这里是 \( 0\) 当然也可以是其他数字,比如 均值 可能比 \( 0\) 会更好一些,有了第一步那么后面就可以一步一步的迭代计算了,得到第 \( m\) 轮的模型
\( H_m(x)\) 为第 \( m\) 的模型, \(H_{m-1}(x)\) 是上一轮的已知的模型, \( T_m(x;\Theta)\) 就是第 \(m\) 轮需要加进来的树模型,是需要学习的,这里 \( \Theta\) 表示这棵树的结构,包括 区域划分 和各区域内的预测值 ,我们想要让这个 \( T_m(x;\Theta)\) 加进来之后模型变得更好也就是损失变得更小,我们就可以这么估计这个 \( T_m(x;\Theta)\)
这样优化这个函数,来求得 \( \hat\Theta_m\) 也就是第 \( m\) 棵树 \( T_m(x;\Theta)\) 的参数,确定了参数也就确定了加进来的这棵树是什么样的了,就得到了第 \( m\) 轮的模型,下一轮再加进来一棵树直到最后损失收敛,这里 \( L(a, b)\) 表示二者的某种损失函数 \( Loss Function\)
回归问题中一般用 均方误差 损失
分类问题中一般用 \( logistic\) 损失
这里以均方误差损失为例,上式的损失函数就是
residual 就是所谓的残差 \( y^{(i)}-H_{m-1}(x^{(i)})\) ,即本轮学习之后仍然存在的误差,本轮需要加进去的这棵树就是照着残差去学习出来的树结构,其实也可以从梯度的角度来理解,针对平方损失函数 \( L(y, f(x)) = \frac{1}{2}(y-f(x))^2\) , \( f(x)\) 为某一轮结束时的累加起来的模型,此时应该沿着 损失的负梯度方向 继续前进,也就是
其实也是一样的,最终得到的模型就是 \( H(x) = \sum_{m=1}^{M}{T_m(x;\Theta)}\) ,将 \( m\) 轮学习到的树模型累加在一起作为最终模型输出
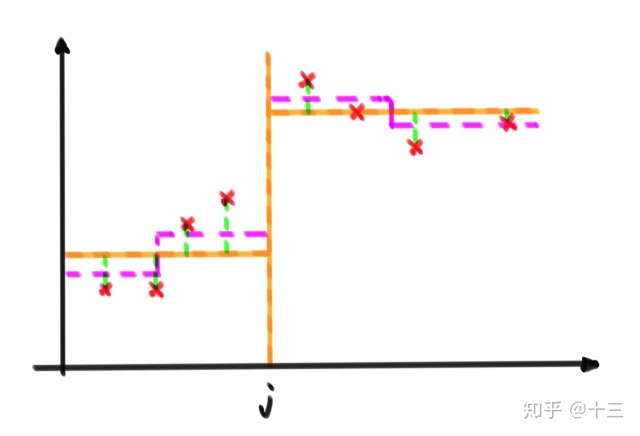
下图比较清晰的解释了这一过程, 红色的✘ 是数据点, \( j\) 为找到的分割点(这里是一颗CART),左右两部分分别的预测值就是 橙色的实折线 ,发现并没有拟合的特别好, 绿色的虚线 为预测值到真实值的误差,也就是我们所谓的残差,这时候就可以将绿色这部分的值作为另一颗CART训练的数据,最终形成 紫色的虚折线,很明显紫色的线要比橙色的线做的要好
但是 残差的这种形式只针对于回归问题中的平方损失函数,如果换了其他损失函数就没这么简单了,但是计算方式和上面推导的过程是一样的,只不过不能简单是用残差来学习本轮的树模型,而是要沿着损失的负梯度 \( -\frac{\partial L(y, f(x))}{\partial f(x)}\) 的方向来学习
GBDT也有一些弊端 ,虽然有尚可的解决方案但是效果还是不是很好,主要有以下几点:
1. 对于平方损失来说,对 噪声数据很敏感 ,因为此时损失为残差的平方,这样就加大了模型对这些噪声数据的关注度,容易过拟合,解决办法就是换一种损失函数,让损失不会过分放大,比如说 绝对值损失 \( L(y, f(x)) = |y-f(x)|\) ,或者 Huber损失 来解决
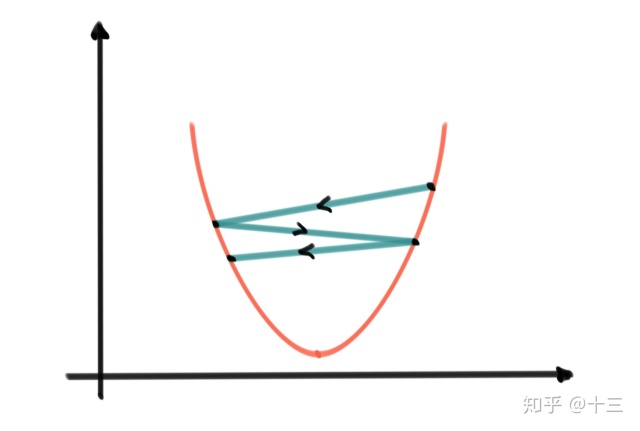
2. 树模型”准确“的照着残差的方式去学习,很容易出现 Z形学习曲线 ,步长过大,让模型更不易收敛,解决的办法就是为 \( T_m(x;\Theta)\) 添加一个shrinkage ,变成 \( \epsilon T_m(x;\Theta)\) 让步子小一点,这里 \( \epsilon\) 类似于学习速率一般为一个很小的小数来控制每一次学习的幅度
针对GBDT的各种问题,陈天奇博士在论文中给出了更优的解决办法,就是 XGBoost,基于GBDT的思想做出了各种优化,比如算法层面添加正则化项 让模型更简单,一定程度的避免过拟合,还有在损失函数上进行了 二阶泰勒展开 ,提升模型的精度,还有工程层面尽最大可能的并行处理 ,让训练效率更高,更有在特征工程层面上对 缺失值的处理 优化等等,这些优化也让XGB在一些竞赛中取得了很好的成绩
加强版的GBDT XGBoost
XGB最终的模型和GBDT是一样的,为 \( H(x) = \sum_{m=1}^{M}{T_m(x; \Theta)},T_m\in F\) ,也是基于加法的树模型,但是XGB的损失函数相较于GBDT略有不同,这里加了正则化项,在回归问题中正则化项一般有L1-norm(LASSO) \( \lambda||\theta||_1\) 和 L2-norm(Ridge) \( \lambda||\theta||_2\) 这里 \( \theta\) 为各个特征的系数,在这里即为 树模型的结构复杂度 ,比如 叶子节点的数量 和 树的深度 还有 叶子节点中多个样本的L2-norm ,XGB中第 \( m\) 轮的损失函数就为
其中 \( \Omega(T_m)\) 就是XGB中的正则化项,代表本轮需要加进去的这个树模型的复杂度,这里我们同时考虑回归问题中的均方误差损失和 \( H_m(x)= H_{m-1}(x) + T_m(x;\Theta)\) ,可以进一步得出损失函数
此时其实就是加了 正则化项的残差 拟合方式,如果换了其他损失这里还是不容易解决的,XGB的关键点就在这一处,XGB用了泰勒公式的二阶展开式来对损失近似求解 ,同时也使得XGB更通用,只要损失函数二阶可导都可以应用这种方法处理,用户甚至可以自己定义二阶可导的损失函数
首先 泰勒公式 的二阶展开式为
其次需要解释的是 \( l(y^{(i)},H_{m-1}(x^{(i)}) + T_m(x;\Theta))\) 中 \( T_m(x;\Theta)\) 相较于从 \( 1\) 到 \( m-1\) 轮的所有树相加是很小的,所以泰勒展开式中的 \( \Delta x\) 就是这里的 \( T_m(x;\Theta)\) ,而 \( f(x)\) 对应这里的就是 \( l(y^{(i)}, H_{m-1}(x^{(i)}))\) ,我们的损失函数就可以写成
其中 \( g\) 为一阶导, \( h\) 为二阶导,这里 \(l(y^{(i)}, H_{m-1}(x^{(i)}))\) 为 常数项 所以在损失函数中可以舍掉,主要关注 \( g\) 和 \( h\) ,这里为了计算方便依旧 考虑平方损失函数
最终的需要关注的损失函数就是
也就是说主要求出当前第 \( m-1\) 轮的模型的一阶导数和二阶导数然后最优化 \( Loss\) 就可以得到每一轮的 \( T_m(x;\Theta)\)
然后考虑正则化项 \( \Omega(T_m(x;\Theta))\) ,我们用 叶子节点的数量 \( T\) ,和 每个叶子节点中的得分 \( w\) (虽然一个叶子节点中有多个样本,但是是用一个值来作为这个叶子节点的输出的)来衡量模型的复杂度,以下图解引用陈天奇博士PPT中的图解,PPT中表示为 \(\Omega(f_t)\)
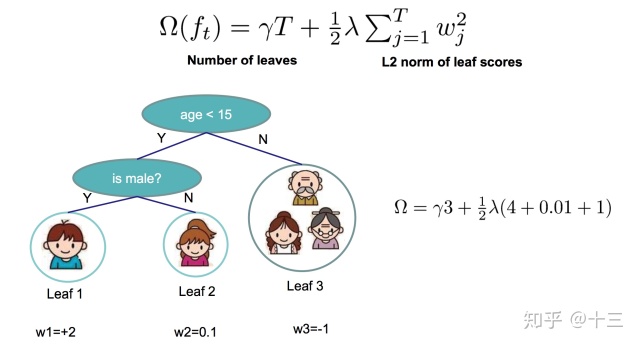
这里 \( \gamma\) 和 \( \lambda\) 就是一个因子系数,表示正则化项中更关注哪一部分, 用 \( I_j\) 表示第 \( j\) 个叶子节点中的样本集合 ( \( j\) 对于CART来说就是从根节点开始不断的找到收益最大的分裂点 \( s\) 来二划分 ),此时损失函数就可以转化成下面这样
然后继续定义 \( \sum_{i\in I_j}^{}{g^{(i)}} = G_j\) , \(\sum_{i\in I_j}^{}{h^{(i)}} = H_j\) ,最终等式就可以写成
此时令 \( Loss\) 的导数为 \( 0\) 即可求得
此时 \( Loss\) 就可以简洁为

到此为止一切都做的很不错,但是有一个问题就是 \( j\) ,我们并不知道这棵树是怎么划分的,也就是说第 \( j\) 个叶子节点我们并不知道,这时候 暴力穷举树结构肯定是不可取 的,就需要根据我们的损失函数,寻找收益最大的分裂点来进行划分 ,具体的步骤是这样的,这里定义 分裂点 \( s\) 把样本划分为左右两部分 (类似CART的划分方式,只不过用的目标函数不同)
1. 计算 分裂前 的收益
2. 计算 分裂后 的收益
3. 分裂前收益-分裂后收益 ( \( \frac{1}{2}\) 这个可以舍掉),找出 收益最大 的分裂点 \( s\)
此时XGB中也可以 自动剪枝 ,剪枝主要为两种方式:一种为在 训练过程中通过计算分裂收益判断是否要继续向下分裂 (此时 考虑不到未来的分裂节点会带来正收益的情况 ),二种为生成 完整的树结构之后,自下而上的逆向剪枝
4. 最后计算出树的结构也就确定了第 \( m\) 轮需要加入的树模型 \( T_m(x;\Theta)\) ,形成最终的模型,这里也可以加一个 shrinkage 的学习速率 \(\epsilon\) ,来控制学习速度,给后面的学习留下一定的空间,最终的模型即是
😛