在机器学习问题中,基本上都是基于特定的损失函数,来迭代优化这个函数值,既然是损失函数,代表的是损失的多少,所以通常是寻找最小值,梯度下降法即是一种不断寻找函数极值点的方法,通常用“人物下山”来举例子,考虑你现在山上的某一点,你想要快速下山,这个过程有3点是需要确定的,才能完成这个动作
- 我一步能迈多远,步子越大当然速度就越快
- 方向,当然要往下走,而且是越陡越好
- 走到”谷底“的时候就停止
梯度
梯度即函数收敛过程中,变化最快的方向,这样才不会走偏而“绕远”,这里从微积分开始说起
微积分,可以理解为函数某点上的斜率,下面大概举几个例子
梯度,就是多变量微分,最终的梯度也就是1个向量, 代表在各个方向上的分量 \(\theta\) 在这时为一个向量
梯度就是那个下降最快的方向,具体的梯度下降的公式下面解释,这里举一个线性回归的例子
线性回归
我们有若干数据,想要拟合出一条合理的回归线,我们就可以用梯度下降不断迭代求出这条直线的2个参数 \(\theta_0,\theta_1\) ,即 \(f(x) = \theta_0 + \theta_1 x_1\)
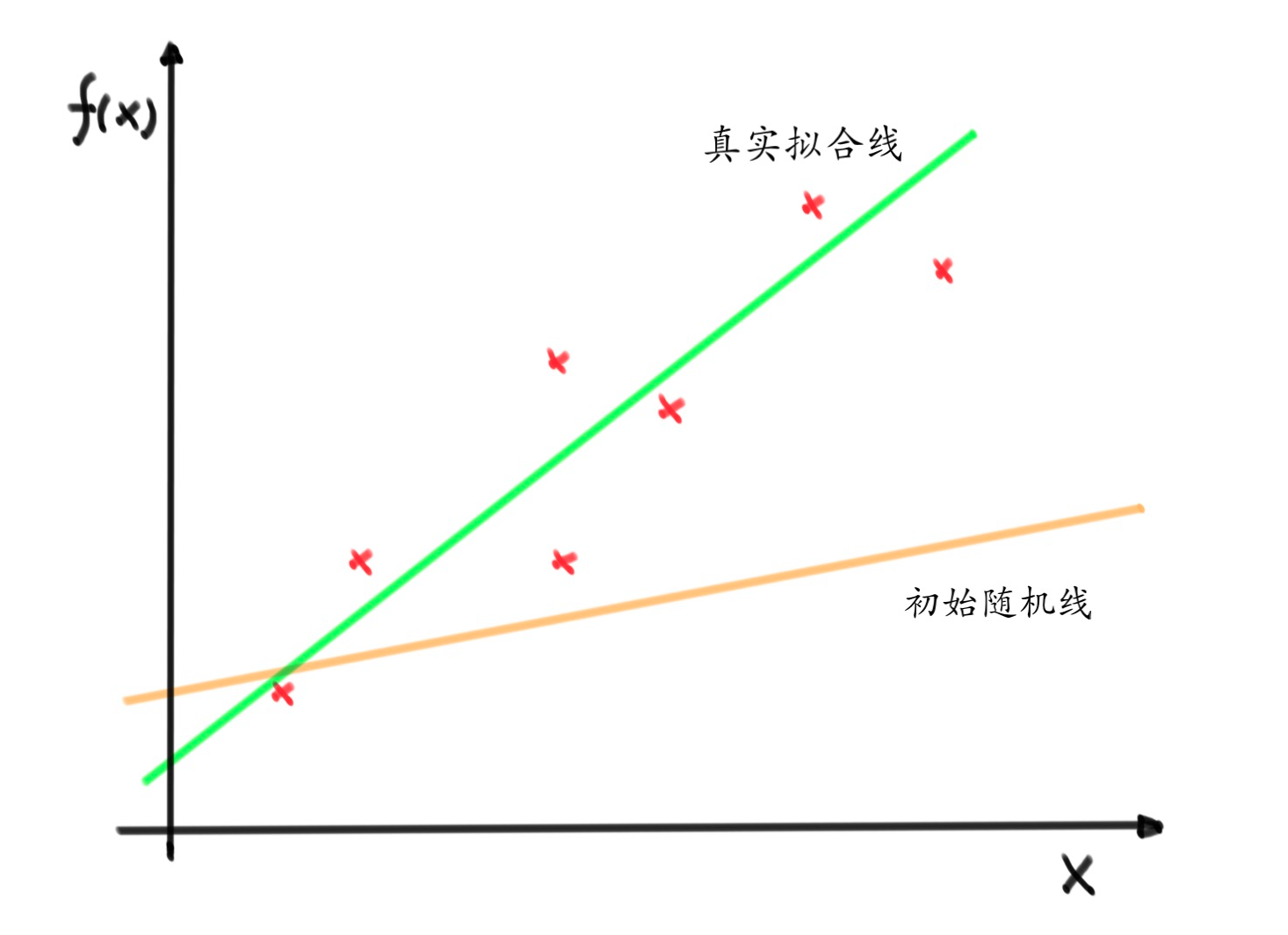
- 这里 红叉表示样本点 ,现在我们想拟合出1条 最合理的直线 (绿色)来代表随机变量的趋势,这时候就可以用梯度下降来解决这个问题
- 思考一个问题,就是我们如何用数学的方式来判断某条直线就是我们想要的直线,显然这条直线不能离样本点太远,否则效果就太差了,要“雨露均沾”的距离样本点足够近才足够好
- 这里用 距离误差平方和 的方式表示,也就是当前的直线到样本点的距离的平方的和,我们想要优化的就是 样本点到直线的距离的平方和为最小, 这时候我们认为该条直线就是我们所要的,下面通过这个线性回归的例子来一步一步解释梯度下降
Step 1 . 随机给一个 \(\theta_0, \theta_1\) ,这里就是橙色这条线,当然也可以是其他的值,我们假设的函数叫做 \(H(\theta)\)
Step 2 . 计算样本点到橙色线的距离,这个误差项我们叫做 损失值 , 误差函数叫 损失函数 即为各点到 \(H(\theta)\) 的距离平方和
这里 \(x^{(i)}, y^{(i)}\) 为第 i 个坐标点(x, y); \(\frac{1}{2}\) 则为一种数学上的 方便计算 的系数,使得求偏导数的时候与平方项能约掉,对优化问题并不产生影响
Step 3 . 我们想要求得的就是上面的损失函数的最低点,这里就用到梯度下降的算法,计算偏导数
- \(\alpha\) 代表 步长 , 即是每次迭代的速度, \(\alpha\) 的大小设置是1个经验值,太大容易错过最低点直接一步迈到另外一边的山腰上,太小容易走得太慢,走半天还没走到山底
- \(\theta\) 是一个向量,所以 \(\theta_j\) 要 同时更新
- ? 为什么要向梯度的负方向移动,从下图很容易看出来,最低点的右边梯度>0则向左移动,反之向右移动,即总是向梯度的反方向移动
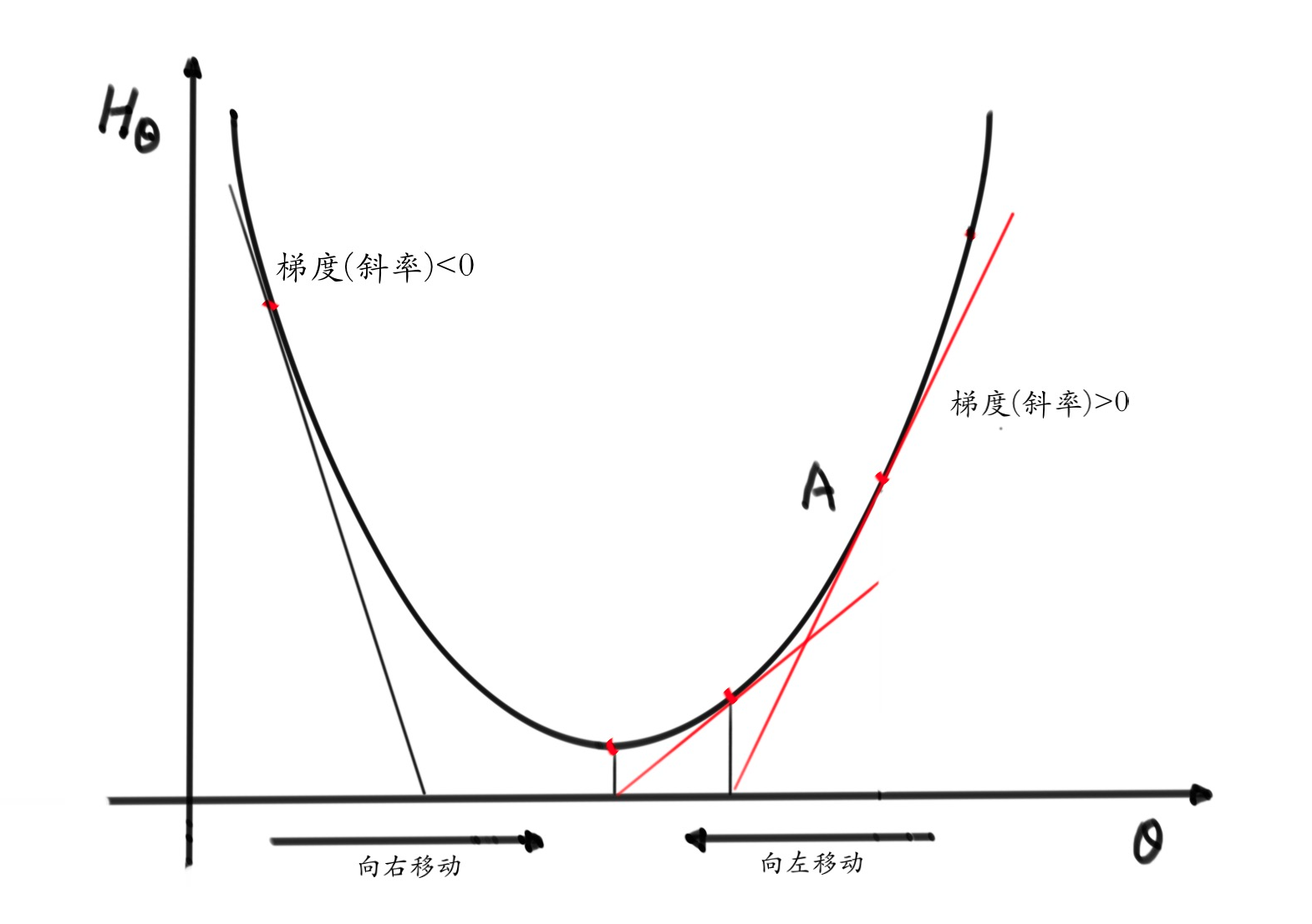
Step 4 . 如上图展示,我们要做的就是从 \(A\) 点一步一步走到最低点,得到 损失函数 的最小值,我们就认为,此时的 \(\theta\) 为最优状态
举个例子
假设我们有一个 \(J(\theta) = \theta_0^2 + \theta_1^2\) , 那么\(\frac{\partial J(\theta)}{\partial \theta} = 2\theta_0 + 2\theta_1\) , 这里 \(\alpha=0.1\) ,初始化 \( \theta^{(0)} = [1, 3]\) , 我们已知这个函数的最小值为 \([0, 0]\)
总结
损失函数的优化方法有很多,即便是梯度下降也有很多更好的实现方法,比如工程上更常用的小批量梯度下降或者随机梯度下降,本文讨论是最基本的批量梯度下降,即每”下降“一次都要用全量的数据来计算,在实际生产环境中这个数据量往往是很大的,这么做很影响算法的性能,所以提出了小批量梯度下降或者随机梯度下降,思想就是用比较少的数据来计算梯度,降低计算量,但是算法核心是不变的。
😛