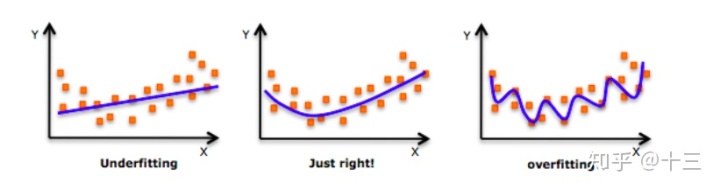
今天的话题从线性回归开始,在应对线性回归问题的时候,实质上就是训练1个函数 \(f(X) = \theta^TX = Y\),这个等式可以通过我之前的文章 最小二乘法 来计算,即 \(\theta = (X^TX)^{-1}X^TY\) ,但是由于最小二乘法需要计算矩阵的逆,所以有很多的限制,比如矩阵不可逆 ,又或者矩阵中有 多重共线性 的情况,会导致计算矩阵的逆的时候行列式接近0,对数据很敏感,还有可能在训练模型的时候有过拟合的情况出现(如下图,第3个图的曲线精确的学习到了所有的数据点,显然就是过拟合了),下面这里通过解决实际问题,一点一点推算出来解决这些问题的2种方法:L1 和 L2 正则化。
L2正则化
先说一下L2正则化的思想,开篇提到过,最小二乘法有很多限制和很多弊端,比如 多重共线性 这个问题,由于需要计算矩阵的逆,所以训练出的模型系数往往会比较大_(行列式接近0)_ ,这样模型会很不稳定,所以大牛们就想啊,能不能给最小二乘法加上点 惩罚,让这个系数小一些,模型更稳定,泛化能力更好,于是就有了这个方法。
L2正则化即是在最小二乘法的基础上,加1个对系数的 “惩罚项” ,为了方便计算所以加上的是 L2-norm 的平方,这时候损失函数就为
这里添加了一个 \(\frac{\lambda}{2} ||\theta||_2^2\) 就是 L2 正则化做的事情,是为了考虑损失的同时还要兼顾模型也就是 \(\theta\) 的大小,不让 \(\theta\) 变成1个很大的数,从而避免过拟合或者说让模型更简单,泛化能力更强,然后对 \(J(\theta)\) 求导。
这里根据推导我们就能看出来, \( \alpha\frac{1}{N}\sum_{i=1}^{N}{(H_\theta(x^{(i)})-y^{(i)})x_j}\) 这部分就是普通的 批量梯度下降 ,同时 \( \alpha\) 和 \(\lambda\) 都是一个 小于1 的比较小的数字,所以这里做的就是在每次迭代的时候,把 \( \theta_j\) 再缩小一点, “缩小多少” 这个因子则是由 \( \lambda\) 控制的,通过调整 \( \lambda\) 的大小来调整模型是更关注 损失 还是更关注 模型的复杂度 。
从 最小二乘法 的角度来思考,也可以直接计算 \( \theta\) 的解析解 \( J(\theta) = ||X\theta - Y||_2^2 +\lambda||\theta||_2^2\),这里省略展开过程,可以得到
这样也是可以直接计算出 \( \theta\) 的,只是加上了1个 \(\frac{\lambda}{2}I\) ,这里有2点需要注意
- 有很多普通最小二乘法矩阵不可逆的情况,这里加上了 \( \frac{\lambda}{2}I\) 就变得可逆了,让最小二乘法更通用
- \( X^TX\) 由于 \( x_0\) 这项所以是 \( (n+1)\times(n+1)\) 的矩阵,这里的 \( I\) 也应该是 \( (n+1)\times(n+1)\) 的,但是有一点不同就是这里的 \( I\) 实际上是
因为这里并不需要对 \( \theta_0\) 这个 偏置项 做缩放,这种线性回归方法我们也叫做 岭回归(Ridge Regression) ,即加了 L2-norm 正则化的线性回归。
L1正则化
这里和L2有点不同: L2虽然很优秀,计算出来的系数更稳定,但是多重共线性仍然存在,有没有一种类似这种添加惩罚项的办法来解决掉多重共线性的问题?其实这里很自然的就想到,把L2 正则化中的惩罚项替换成 L0-norm (系数中非0的个数),这样模型就更简单了,无关的维度系数为0,即是去除掉该维度,但是L0-norm 又有很多问题(函数非连续,很难求解),所以用 L1-norm (系数的绝对值)来近似地取代 L0-norm 。
L1 正则化的推导公式跟 L2 正则化的推导类似,区别主要在添加的惩罚项部分,所以为了理解这里可以这么写这个损失函数
\( J_0(\theta)\) 为一般线性回归部分, \(J_1(\theta)\) 为L1-norm 部分 \(\frac{\partial J(\theta)}{\partial \theta} = \lambda\times sgn(\theta)+ \frac{\partial J_0(\theta)}{\partial \theta}\) ,梯度下降更新 \(\theta\) 的时候即是 \(\theta_j^{'} = \theta_j - \alpha \lambda sgn(\theta_j) - \alpha\frac{\partial J_0(\theta)}{\partial \theta}\)
其中 \(\alpha \lambda sgn(\theta_j)\) 项,当 \(\theta_j > 0\) 时,更新后 \( \theta_j\) 变小,当 \(\theta_j < 0\) 时,更新后 \( \theta_j\) 变大,所以这里的效果就是让 \( \theta_j\) 往0上靠拢,让 \( \theta\) 中尽可能多的为0,也就是常说的让 \( \theta\) 更稀疏 ,所以说 L1 正则化可以 优化过拟合和做特征选择 ,因为为0的 \( \theta_j\) 就是不重要的特征,但是这里有一个问题,当 \( \theta_j=0\) 的时候怎么办?因为此时 \(\theta\) 是不可导的,所以粗暴一点就是按照普通最小二乘法的方式去迭代,也就是去掉 \( \alpha \lambda sgn(\theta_j)\) 项或者令其为0,这样就解决了,更通用一点的是利用 坐标下降法 来求解,本质就是控制其他维度,单独调整某一个维度的 \( \theta_j\) ,确定之后再继续调整其他的 \( \theta\) ,也可以解决。
这种线性回归方法我们也叫做 LASSO回归(least absolute shrinkage and selection operator),即加了 L1-norm 的惩罚项的线性回归。
总结 LASSO 和 Ridge 回归
相同点: 都是在线性回归的基础上,添加了一个惩罚项,让模型更稳定更简单,泛化能力更强,避免过拟合。
不同点:LASSO 是利用 L1-norm 来逼近 L0-norm的,因为系数可以减小到0,所以可以做特征选择,但是并不是每个点都是可导的,所以计算起来可能会并没有 L2-norm 方便; Ridge 是利用 L2-norm 来使系数不那么大,同时方便计算,但是不会使系数减小到0,所以不能做特征选择,可解释性方面也没有 LASSO 高。
😛