在机器学习中, 朴素贝叶斯 (Naive Bayes)是一系列以假设特征之间强(朴素)独立下运用贝叶斯定理为基础的简单 概率分类器。朴素贝叶斯自20世纪50年代已广泛研究。在20世纪60年代初就以另外一个名称引入到文本信息检索界中,并仍然是 文本分类的一种热门(基准)方法,文本分类是以词频为特征判断文件所属类别或其他(如垃圾邮件、合法性、体育或政治等等)的问题。通过适当的预处理,它可以与这个领域更先进的方法(包括支持向量机)相竞争。它在自动医疗诊断中也有应用。参考朴素贝叶斯分类器
贝叶斯定理
要理解贝叶斯定理其实比较简单,实际上就是常说的 “ 条件概率 ”,所谓条件概率,就是假定事件A发生的基础上,事件B发生的概率,用 \( P(B|A)\) 来表示,叫做“ 给定A时,B的概率 ”。

考虑样本空间 \( \Omega\) 中有2个事件A和B,其中 相交 的部分为 \( A\cap B\) ,这里可以很容易计算出贝叶斯公式
一般的,这里 \( P(A|B)\) 叫做 似然概率, \( P(B)\) 叫做先验概率 , \( P(A)\) 是1个归一化系数,跟我们要计算的”给定 \( A\) 时 \( B\) 的概率“中的 \( B\) (即我们主要关注的点)是无关的
公式推导
Step 1 . 实际情况中我们遇到的问题一般是,给定1个数据样本,根据朴素贝叶斯对之做出分类,即 \(P(C |X)\) ”给定数据样本 \(X\) ,分类为 \(C\) 的概率“,根据贝叶斯公式有
Step 2 . 这里 \(X\) 要转化成跟 \(C\) 相关的话就可以这样做,即
Step 3 . 所以这里朴素贝叶斯公式可以转化成如下( \(C \in (C_1, C_2...C_j)\) 个分类)
Step 4 . 重点来了,这里的 \(X\) 是1个n维的数据 \(x_1,x_2,...,x_n\) ,这里讨论的是朴素贝叶斯,之所以称为朴素,就是这里有1个前提: \(X\) 中的每个维度都是相互独立 的( 虽然现实生活中往往并不是这样,但是即便是我们假定的有一些偏差,但是还是可以解决很多问题,也说明了朴素贝叶斯的强大 ),所以这里我们主要专注研究 \(P(X|C_j)\)
Step 5 . 最后就可以整理成
这其中 \(P(C)\times \prod_{i=1}^{n}P(x_i|C)\) 为主要关注的点,与 \(P(C|X)\) 正相关 ,下面通过处理实际问题的例子具体感受一下朴素贝叶斯的神奇
“是否要去看电影”问题
比如说我喜欢去看电影,但是电影并不是想看就随时能看的,所以这里就要通过一些信息来做判断,判断我”是否要去看电影“
这里有我近10次看电影的记录,大概总结起来主要有4个维度来影响我是否要去看电影,分别是:是否周末,天气好坏,地点远近,电影评分的高低,然后现在的情况是:是周末,天气坏,地点远,评分高的电影 ,但是我现在不想权衡到底是看还是不看,这时候朴素贝叶斯就能很好的解决我的问题。
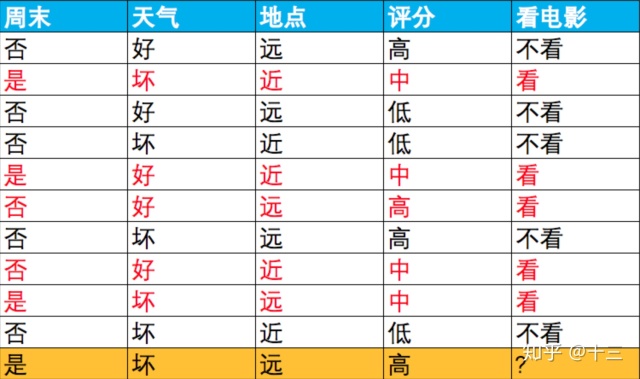
根据朴素贝叶斯公式,这里写的通俗一些,其实就是数数,比如 \( P(看)\) 就是在所有样本中” 看 “占的比例,\( P(是周末|看)\) 就是在看的5天中有3天是周末,所以概率就为 \( \frac{3}{5}\)
这里有2点需要说明注意一下:
- 注意到每个公式的第一个“ 等于号 ”实际上不是 “ \( =\) ”,而是“ \(\Rightarrow\) ”,这里代表 正相关 ,因为这里并不是严格的等于概率的,还需要加上 \( P(X)\) 这个归一化系数,可以直接比较他们的大小,因为分母是不变的嘛,但是并不代表计算的是概率,实际上做归一化之后就是所求概率了即
-
注意到 \( P(是周末|不看)\) “ 不看电影的时候,是周末 ”,这种情况在我们样本中并没有发生所以概率就是0,但是如果其中之一为0,概率连乘之后会导致整个计算结果也为0,所以这里需要做一个 平滑,这种用1个很小的数代替0的办法一般叫做 拉普拉斯平滑 ,通常有2种方法。
- 指定一个很小的数字比如 \( 1 \times 10^{-4}\)
- 在“ 垃圾邮件分类器 ”的时候也可能会“ 分子+1 ”和“ 分母+总词数 ”这种办法,但是思想是一样的
特点
优点:
- 算法简单,可解释性强
- 分类效率较高,只是进行普通的数字运算
缺点:
- 由于 “ 朴素 ” 的强假设,分类的准确率会有所牺牲,比如在做 “ 垃圾邮件分类 ” 的时候,我们知道,一封邮件中的词不是相互独立的,比如说 “ 我想喝xxx ”,这里 xxx 大概率是一种饮品,而不是 “ 电脑 ”, “ 手机 ” 等其他词汇,这时就可能会导致分类错误的情况。
😛